Context Scenes version 4 (to be deprecated)
This page describes version 4 of the ContextScene file format. Reality Analysis still supports this format to ensure backward compatibility. Please prefer the latest version.
A ContextScene is a metadata file designed to manipulate raw reality data like photos, maps, meshes and point cloud. It also stores extra metadata on these reality data, like photo position, detected objects, etc. Though not mandatory, the following assumes that you are familiar with the Reality Management Service and its Reality Management API. If not the case, consider Reality Management Service as a set of directories, referred to as entries, with a universally unique identifier (UUID). Depending on what they store, these entries have a type, ContextScene being one of them. Other types involved here will be images (CCImageCollection), meshes (3SM, 3MX) and point clouds (LAS, LAZ, OPC, PointCloud). Check existing types on Reality Data Properties's page.
A ContextScene is persisted as an XML file. Name the file ContextScene.xml when storing in Reality Management Service.
1) Photos

To refer to some of the photos in a directory and not all of them, a ContextScene adds one entry per photo. Each photo has a unique id which is used to refer to the given photo in other parts of the ContextScene file. See the examples below.
<?xml version="1.0" encoding="utf-8"?>
<ContextScene version="4.0">
<PhotoCollection>
<Photos>
<Photo id="0">
<ImagePath>0:IMAGE_1059.JPG</ImagePath>
</Photo>
<Photo id="1">
<ImagePath>0:IMAGE_1060.JPG</ImagePath>
</Photo>
<Photo id="2">
<ImagePath>0:IMAGE_1061.JPG</ImagePath>
</Photo>
</Photos>
</PhotoCollection>
<References>
<Reference id="0">
<Path>Q:\DataSets\Motos\Images</Path>
</Reference>
</References>
</ContextScene>
Note that the complete path is obtained through a set of references, the prefix n: standing for the reference path of id n. Hence, the first photo above is in Q:\DataSets\Motos\Images\IMAGE_1059.JPG. This mechanism allows easy relocation of the raw reality data, in particular when uploading them to a cloud repository. For example, assume the photos in Q:\DataSets\Motos\Images have been uploaded to Reality Management Service in a CCImageCollection entry of uuid 7c00e184-5913-423b-8b4c-840ceb4bf616, then you just have to modify the above ContextScene this way to point to the Reality Management Service version of the photos:
...
<Reference id="0">
<Path>rds:7c00e184-5913-423b-8b4c-840ceb4bf616</Path>
</Reference>
...
2) Photos with positions

It is sometimes required to indicate where the photos are taken from (for 3D search) or even in which direction and with which exact camera (for 2D to 3D mapping). Position and orientation are stored using Pose, while the camera parameters use a Device. Here is an example where the photos are geo-localized. In this case, we also need a Spatial Reference System (SRS). SRS are given through a definition string (EPSG, WKT, …) and referred via their id. All the poses are given in a common SRS. Here is a sample:
<?xml version="1.0" encoding="utf-8"?>
<ContextScene version="4.0">
<SpatialReferenceSystems>
<SRS id="2">
<Definition>EPSG:32629</Definition>
</SRS>
</SpatialReferenceSystems>
<PhotoCollection>
<SRSId>2</SRSId>
<Poses>
<Pose id="0">
<Center>
<x>758987.198998479</x>
<y>4066970.60510875</y>
<z>39.1859999997541</z>
</Center>
</Pose>
<Pose id="1">
<Center>
<x>758989.05099848</x>
<y>4066972.78710875</y>
<z>39.1749999979511</z>
</Center>
</Pose>
<Pose id="2">
<Center>
<x>758990.900998479</x>
<y>4066974.97210875</y>
<z>39.1619999995455</z>
</Center>
</Pose>
</Poses>
<Photos>
<Photo id="0">
<ImagePath>0:Track_B-CAM2-236_2017.05.11_08.17.43(520).jpg</ImagePath>
<PoseId>0</PoseId>
</Photo>
<Photo id="1">
<ImagePath>0:Track_B-CAM2-235_2017.05.11_08.17.43(242).jpg</ImagePath>
<PoseId>1</PoseId>
</Photo>
<Photo id="2">
<ImagePath>1:Track_B-CAM3-234_2017.05.11_08.17.42(965).jpg</ImagePath>
<PoseId>2</PoseId>
</Photos>
</PhotoCollection>
<References>
<Reference id="0">
<Path>Q:\Datasets\Railroad\planar2</Path>
</Reference>
<Reference id="1">
<Path>Q:\Datasets\Railroad\planar3</Path>
</Reference>
</References>
</ContextScene>
3) Photos with orientations

In this case, the directions in which the photos are taken are provided, using a matrix. The camera parameters are also given using a device entry. Jobs relying on 2D+3D reasoning usually involve such advanced ContextScenes (drones, mobile mapping, etc.). Check the Reality Modeling User Guide for concepts and norms used by Bentley Systems. In the following example, 3 photos are taken with the same camera. Poses are not geo-referenced; a local system is used (no SRS)
<?xml version="1.0" encoding="utf-8"?>
<ContextScene version="4.0">
<PhotoCollection>
<Devices>
<Device id="0">
<Type>perspective</Type>
<Dimensions>
<width>1920</width>
<height>1080</height>
</Dimensions>
<PrincipalPoint>
<x>959.325756354222</x>
<y>540.064799475902</y>
</PrincipalPoint>
<FocalLength>1161.90449945652</FocalLength>
<RadialDistortion>
<k1>-0.130619227934255</k1>
<k2>0.11343372341057</k2>
<k3>-0.0194519247358129</k3>
</RadialDistortion>
<TangentialDistortion>
<p1>0</p1>
<p2>0</p2>
</TangentialDistortion>
<AspectRatio>1</AspectRatio>
<Skew>0</Skew>
</Device>
</Devices>
<Poses>
<Pose id="0">
<Center>
<x>-0.242398388617219</x>
<y>-1.31312823176956</y>
<z>-0.170965236298314</z>
</Center>
<Rotation>
<omega>-1.71248177918815</omega>
<phi>0</phi>
<kappa>0.000184858673830527</kappa>
</Rotation>
</Pose>
<Pose id="1">
<Center>
<x>-0.120339121135225</x>
<y>-1.30028905810778</y>
<z>-0.17185130833636</z>
</Center>
<Rotation>
<omega>-1.71250988284902</omega>
<phi>-0.0117559476346202</phi>
<kappa>-0.000475042115853361</kappa>
</Rotation>
</Pose>
<Pose id="2">
<Center>
<x>0.00121763429965454</x>
<y>-1.29989155916196</y>
<z>-0.166334627769606</z>
</Center>
<Rotation>
<omega>-1.71273910713164</omega>
<phi>-0.0528726572200851</phi>
<kappa>-0.00675225403620392</kappa>
</Rotation>
</Pose>
</Poses>
<Photos>
<Photo id="0">
<ImagePath>0:vlcsnap-2015-07-24-09h50m51s786_写真.jpg</ImagePath>
<DeviceId>0</DeviceId>
<PoseId>0</PoseId>
</Photo>
<Photo id="1">
<ImagePath>0:vlcsnap-2015-07-24-09h51m55s443_写真.jpg</ImagePath>
<DeviceId>0</DeviceId>
<PoseId>1</PoseId>
</Photo>
<Photo id="2">
<ImagePath>0:vlcsnap-2015-07-24-09h52m39s752.jpg</ImagePath>
<DeviceId>0</DeviceId>
<PoseId>2</PoseId>
</Photo>
</Photos>
</PhotoCollection>
<References>
<Reference id="0">
<Path>rds:7c00e184-5913-423b-8b4c-840ceb4bf616</Path>
</Reference>
</References>
</ContextScene>
4) Orthophoto
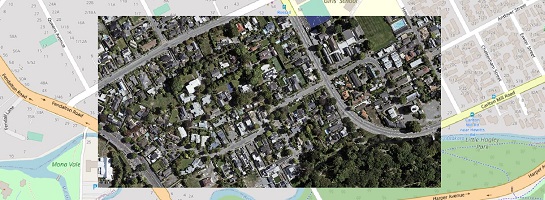
An orthophoto, or a map, is an aerial photograph that has been geometrically corrected or 'ortho-rectified' such that the scale of the photograph is uniform and utilized in the same manner as a map. It is usually split into tiles, each of them having a 2D location in a given SRS. Introducing a specific type of device, an orthotile, to describe scale parameters and adding 2D location coordinates to photos, we simply extend the ContextScene format to describe an orthophoto. Here is a sample where tiles are 3200x4800 images and the resolution is 7.5cm per pixel. The location is the position of the upper-left corner pixel of the image. Note that the y axis of the image pixels goes down toward the south. Being in the northern hemisphere, adding 1 to the pixel y coordinates corresponds to removing 7.5cm to the geographic y coordinate, ending with a negative pixel height of -0.075. We also provide a nodata value for pixels where the orthophoto is unknown. Such parameters are common and usually found in the geotiff files or .tfw sister files.
<?xml version="1.0" encoding="utf-8"?>
<ContextScene version="4.0">
<SpatialReferenceSystems>
<SRS id="0">
<Definition>EPSG:2193</Definition>
</SRS>
</SpatialReferenceSystems>
<PhotoCollection>
<SRSId>0</SRSId>
<Devices>
<Device id="0">
<Type>orthotile</Type>
<Dimensions>
<width>3200</width>
<height>4800</height>
</Dimensions>
<PixelSize>
<Width>0.075</Width>
<Height>-0.075</Height>
</PixelSize>
<NoData>-9999</NoData>
</Device>
</Devices>
<Photos>
<Photo id="0">
<ImagePath>0:BX24_500_025022.tif</ImagePath>
<DeviceId>0</DeviceId>
<Location>
<UlX>1569040</UlX>
<UlY>5181360</UlY>
</Location>
</Photo>
<Photo id="1">
<ImagePath>0:BX24_500_025021.tif</ImagePath>
<DeviceId>0</DeviceId>
<Location>
<UlX>1568800</UlX>
<UlY>5181360</UlY>
</Location>
</Photo>
<Photo id="2">
<ImagePath>0:BX24_500_025020.tif</ImagePath>
<DeviceId>0</DeviceId>
<Location>
<UlX>1568560</UlX>
<UlY>5181360</UlY>
</Location>
</Photo>
</Photos>
</PhotoCollection>
<References>
<Reference id="0">
<Path>Q:\DataSets\Christchurch\Images</Path>
</Reference>
</References>
</ContextScene>
5) Orthophoto with height
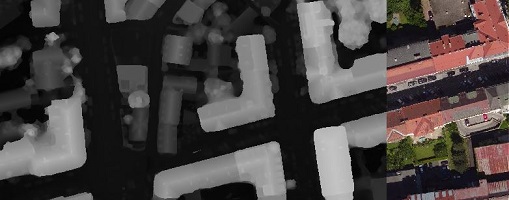
Some orthophotos, often called ortho DSM, provide not only the color of the map at a given position, but also its height. This DSM parameter is given with another tile image with floating pixel values. We simply add a DepthPath entry to the photos. Though not documented above, this depth also makes sense for usual photos when the sensor provides a depth (e.g., an iPhone13 Pro), hence the tag's name.
<?xml version="1.0" encoding="utf-8"?>
<ContextScene version="4.0">
<SpatialReferenceSystems>
<SRS id="0">
<Definition>EPSG:32633</Definition>
</SRS>
</SpatialReferenceSystems>
<PhotoCollection>
<SRSId>0</SRSId>
<Devices>
<Device id="0">
<Type>orthotile</Type>
<Dimensions>
<width>2000</width>
<height>2000</height>
</Dimensions>
<Band>Visible</Band>
<PixelSize>
<Width>0.1</Width>
<Height>-0.1</Height>
</PixelSize>
<NoData>-9999</NoData>
</Device>
</Devices>
<Photos>
<Photo id="0">
<ImagePath>0:rgb_part_1_2.tif</ImagePath>
<DeviceId>0</DeviceId>
<Location>
<UlX>533550.937633621</UlX>
<UlY>5212434.93763362</UlY>
</Location>
<DepthPath>0:dsm_part_1_2.tif</DepthPath>
</Photo>
<Photo id="1">
<ImagePath>0:rgb_part_1_1.tif</ImagePath>
<DeviceId>0</DeviceId>
<Location>
<UlX>533350.937633621</UlX>
<UlY>5212434.93763362</UlY>
</Location>
<DepthPath>0:dsm_part_1_1.tif</DepthPath>
</Photo>
</Photos>
</PhotoCollection>
<References>
<Reference id="0">
<Path>rds:7c00e184-5913-423b-8b4c-840ceb4bf616</Path>
</Reference>
</References>
</ContextScene>
6) Meshes

Meshes are given in a MeshCollection section. 3SM and 3MX formats are currently supported. When geo-referenced, these formats store their SRS on their side, so that providing SRS in the ContextScene file is not mandatory. If you set SRS in the ContextScene, which can be done for the whole mesh collection or per mesh, it overrides the one in the mesh. The same is true for bounding boxes. See the following two examples:
<?xml version="1.0" encoding="utf-8"?>
<ContextScene version="4.0">
<SpatialReferenceSystems>
<SRS id="1">
<Definition>EPSG:25829</Definition>
</SRS>
</SpatialReferenceSystems>
<MeshCollection>
<SRSId>1</SRSId>
<Meshes>
<Mesh id="0">
<Path>0:Production_1_3sm.3sm</Path>
</Mesh>
</Meshes>
</MeshCollection>
<References>
<Reference id="0">
<Path>Q:\Datasets\Bridge</Path>
</Reference>
</References>
</ContextScene>
<?xml version="1.0" encoding="utf-8"?>
<ContextScene version="4.0">
<MeshCollection>
<Meshes>
<Mesh id="0">
<Path>0:Production_1.3mx</Path>
<BoundingBox>
<xmin>-100</xmin>
<ymin>-120</ymin>
<zmin>10</zmin>
<xmax>100</xmax>
<ymax>80</ymax>
<zmax>35</zmax>
</BoundingBox>
</Mesh>
</Meshes>
</MeshCollection>
<References>
<Reference id="0">
<Path>rds:7c00e184-5913-423b-8b4c-840ceb4bf616</Path>
</Reference>
</References>
</ContextScene>
7) Point Clouds

Similarly, point clouds are given in a PointCloudCollection section. Usual formats are supported in a ContextScene file, as well as OPC and POD. Neither SRS nor BoundingBox are read from the point cloud files themselves, so you have to provide one in the ContextScene, if needed. Here are some examples:
<?xml version="1.0" encoding="utf-8"?>
<ContextScene version="4.0">
<SpatialReferenceSystems>
<SRS id="1">
<Definition>EPSG:25829</Definition>
</SRS>
</SpatialReferenceSystems>
<PointCloudCollection>
<SRSId>1</SRSId>
<PointClouds>
<PointCloud id="0">
<Path>0:point_cloud.opc</Path>
</PointCloud>
</PointClouds>
</PointCloudCollection>
<References>
<Reference id="0">
<Path>Q:\Datasets\Spain</Path>
</Reference>
</References>
</ContextScene>
<?xml version="1.0" encoding="utf-8"?>
<ContextScene version="4.0">
<SpatialReferenceSystems>
<SRS id="0">
<Definition>EPSG:25829</Definition>
</SRS>
</SpatialReferenceSystems>
<PointCloudCollection>
<SRSId>0</SRSId>
<PointClouds>
<PointCloud id="0">
<Path>0:spain.las</Path>
</PointCloud>
</PointClouds>
</PointCloudCollection>
<References>
<Reference id="0">
<Path>Q:\Datasets\Rail</Path>
</Reference>
</References>
</ContextScene>
<?xml version="1.0" encoding="utf-8"?>
<ContextScene version="4.0">
<SpatialReferenceSystems>
<SRS id="1">
<Definition>ENU:36.7127,-6.10034</Definition>
</SRS>
</SpatialReferenceSystems>
<PointCloudCollection>
<SRSId>1</SRSId>
<PointClouds>
<PointCloud id="0">
<Path>0:PointCloud.pod</Path>
</PointCloud>
</PointClouds>
</PointCloudCollection>
<References>
<Reference id="0">
<Path>rds:7c00e184-5913-423b-8b4c-840ceb4bf616</Path>
</Reference>
</References>
</ContextScene>
Please note the ENU:LATITUDE,LONGITUDE SRS definition used by the above example is not standard. You might encounter this SRS definition in files generated by Reality Modeling (check Reality Modeling User Guide).
8) Annotations
So far, we have seen how to refer to raw reality data or to add extra metadata information like localization. The next section is specific to Reality Analysis and is usually filled by the analysis. It consists of Annotations which specify parts of the reality data and what has been detected. These parts could be a position, a geometric shape, every pixel, every point of the point cloud, etc. What has been detected is called a label or class (a traffic sign, a power line, ground, vegetation, etc.).
Available Annotations
2D objects

Objects are detected in photos as boxes aligned with the axis. In this case, the Annotations section of the ContextScene consists of the set of labels (names and ids), followed by detected boxes (coordinates and label) in every photo. Coordinates are relative to the photo size between 0 and 1. A confidence for the detected object might be provided between 0 and 1. Note that the objects have an id which is specific to the photo it which has been detected in: two objects having the same id are not supposed to correspond to the same real object seen in two different images. Here is a small example:
<?xml version="1.0" encoding="utf-8"?>
<ContextScene version="4.0">
<PhotoCollection>
<Photos>
<Photo id="0">
<ImagePath>0:IMG_1059.JPG</ImagePath>
</Photo>
<Photo id="1">
<ImagePath>0:IMG_1060.JPG</ImagePath>
</Photo>
<Photo id="2">
<ImagePath>0:IMG_1061.JPG</ImagePath>
</Photo>
</Photos>
</PhotoCollection>
<Annotations>
<Labels>
<Label id="3">
<Name>car</Name>
</Label>
<Label id="4">
<Name>motorcycle</Name>
</Label>
</Labels>
<Objects2D>
<ObjectsInPhoto>
<PhotoId>0</PhotoId>
<Objects>
<Object2D id="0">
<LabelInfo>
<Confidence>0.998535</Confidence>
<LabelId>3</LabelId>
</LabelInfo>
<Box2D>
<xmin>0.0319100581109524</xmin>
<ymin>0.537032723426819</ymin>
<xmax>0.374318599700928</xmax>
<ymax>0.66499537229538</ymax>
</Box2D>
</Object2D>
<Object2D id="1">
<LabelInfo>
<Confidence>0.9965625</Confidence>
<LabelId>3</LabelId>
</LabelInfo>
<Box2D>
<xmin>0.877565920352936</xmin>
<ymin>0.4940065741539</ymin>
<xmax>1</xmax>
<ymax>0.62068098783493</ymax>
</Box2D>
</Object2D>
</Objects>
</ObjectsInPhoto>
<ObjectsInPhoto>
<PhotoId>1</PhotoId>
<Objects>
<Object2D id="0">
<LabelInfo>
<Confidence>0.9978036</Confidence>
<LabelId>3</LabelId>
</LabelInfo>
<Box2D>
<xmin>0</xmin>
<ymin>0.506300926208496</ymin>
<xmax>0.29727840423584</xmax>
<ymax>0.642435193061829</ymax>
</Box2D>
</Object2D>
<Object2D id="1">
<LabelInfo>
<Confidence>0.9839146</Confidence>
<LabelId>4</LabelId>
</LabelInfo>
<Box2D>
<xmin>0.854629874229431</xmin>
<ymin>0.483299434185028</ymin>
<xmax>0.938638925552368</xmax>
<ymax>0.547508895397186</ymax>
</Box2D>
</Object2D>
</Objects>
</ObjectsInPhoto>
<ObjectsInPhoto>
<PhotoId>2</PhotoId>
<Objects>
<Object2D id="0">
<LabelInfo>
<Confidence>0.9977607</Confidence>
<LabelId>3</LabelId>
</LabelInfo>
<Box2D>
<xmin>0.00155594770330936</xmin>
<ymin>0.516191422939301</ymin>
<xmax>0.274634718894958</xmax>
<ymax>0.636547446250916</ymax>
</Box2D>
</Object2D>
</Objects>
</ObjectsInPhoto>
</Objects2D>
</Annotations>
<References>
<Reference id="0">
<Path>Q:\Datasets\Motos</Path>
</Reference>
</References>
</ContextScene>
2D segmentation

To store one label per pixel, what is often called Semantic segmentation, we use a PNG image file. Each pixel is a 16bit unsigned integer set to the label of the corresponding pixel in the annotated photo. The value 65535 is reserved for pixels where the label is unknown. This value is generally used when the ContextScene is the result of a manual annotation: regions where the annotation should be ignored for the Machine Learning training are set to 65535. The PNG files are usually stored aside the ContextScene file in a subfolder. Here is an example:
<?xml version="1.0" encoding="utf-8"?>
<ContextScene version="4.0">
<PhotoCollection>
<Photos>
<Photo id="0">
<ImagePath>0:IMG_1059.JPG</ImagePath>
</Photo>
<Photo id="1">
<ImagePath>0:IMG_1060.JPG</ImagePath>
</Photo>
<Photo id="2">
<ImagePath>0:IMG_1061.JPG</ImagePath>
</Photo>
</Photos>
</PhotoCollection>
<Annotations>
<Labels>
<Label id="0">
<Name>background</Name>
</Label>
<Label id="2">
<Name>bicycle</Name>
</Label>
<Label id="6">
<Name>bus</Name>
</Label>
<Label id="7">
<Name>car</Name>
</Label>
</Labels>
<Segmentation2D>
<PhotoSegmentation>
<PhotoId>0</PhotoId>
<Path>Segmentation2D/0.png</Path>
</PhotoSegmentation>
<PhotoSegmentation>
<PhotoId>1</PhotoId>
<Path>Segmentation2D/1.png</Path>
</PhotoSegmentation>
<PhotoSegmentation>
<PhotoId>2</PhotoId>
<Path>Segmentation2D/2.png</Path>
</PhotoSegmentation>
</Segmentation2D>
</Annotations>
<References>
<Reference id="0">
<Path>rds:7c00e184-5913-423b-8b4c-840ceb4bf616</Path>
</Reference>
</References>
</ContextScene>
2D segmentation in orthophotos

The same type of segmentation applies to orthophoto:
<?xml version="1.0" encoding="utf-8"?>
<ContextScene version="4.0">
<SpatialReferenceSystems>
<SRS id="0">
<Definition>EPSG:2193</Definition>
</SRS>
</SpatialReferenceSystems>
<PhotoCollection>
<SRSId>0</SRSId>
<Devices>
<Device id="0">
<Type>orthotile</Type>
<Dimensions>
<width>3200</width>
<height>4800</height>
</Dimensions>
<Band>Visible</Band>
<PixelSize>
<Width>0.075</Width>
<Height>-0.075</Height>
</PixelSize>
<NoData>-9999</NoData>
</Device>
</Devices>
<Photos>
<Photo id="0">
<ImagePath>0:BX24_500_025022.tif</ImagePath>
<DeviceId>0</DeviceId>
<Location>
<UlX>1569040</UlX>
<UlY>5181360</UlY>
</Location>
</Photo>
<Photo id="1">
<ImagePath>0:BX24_500_025021.tif</ImagePath>
<DeviceId>0</DeviceId>
<Location>
<UlX>1568800</UlX>
<UlY>5181360</UlY>
</Location>
</Photo>
</Photos>
</PhotoCollection>
<Annotations>
<Labels>
<Label id="0">
<Name>background</Name>
</Label>
<Label id="1">
<Name>building</Name>
</Label>
<Label id="2">
<Name>car</Name>
</Label>
</Labels>
<Segmentation2D>
<PhotoSegmentation>
<PhotoId>0</PhotoId>
<Path>BX24_500_025022_mask_.png</Path>
</PhotoSegmentation>
<PhotoSegmentation>
<PhotoId>1</PhotoId>
<Path>BX24_500_025021_mask_.png</Path>
</PhotoSegmentation>
</Segmentation2D>
</Annotations>
<References>
<Reference id="0">
<Path>Q:\Datasets\Christchurch</Path>
</Reference>
</References>
</ContextScene>
3D objects

3D objects are described as 3D boxes. These boxes are given by a range in every direction. An optional rotation might be specified if aligning the box with the axis is too restrictive. It is given as a 3x3 matrix and corresponds to a rotation centered at the center of the box: point [(xmin+xmax)/2,(ymin+ymax)/2,(zmin+zmax)/2] remains the central position of the object. An optional SRS is provided for geo-referenced scenes. Here is an example:
<?xml version="1.0" encoding="utf-8"?>
<ContextScene version="4.0">
<SpatialReferenceSystems>
<SRS id="0">
<Definition>ENU:36.71339,-6.10019</Definition>
</SRS>
</SpatialReferenceSystems>
<Annotations>
<Labels>
<Label id="30">
<Name>light signal</Name>
</Label>
<Label id="29">
<Name>pole</Name>
</Label>
<Label id="28">
<Name>manhole</Name>
</Label>
</Labels>
<Objects3D>
<SRSId>0</SRSId>
<Objects>
<Object3D id="0">
<LabelInfo>
<LabelId>28</LabelId>
</LabelInfo>
<RotatedBox3D>
<Box3D>
<xmin>-18.2450134852094</xmin>
<ymin>-33.4309299351174</ymin>
<zmin>35.994338294097</zmin>
<xmax>-17.6879619720465</xmax>
<ymax>-32.9339199858639</ymax>
<zmax>36.0384178477738</zmax>
</Box3D>
<Rotation>
<M_00>0.923586176565216</M_00>
<M_01>-0.38339088989913</M_01>
<M_02>0</M_02>
<M_10>0.38339088989913</M_10>
<M_11>0.923586176565216</M_11>
<M_12>0</M_12>
<M_20>0</M_20>
<M_21>0</M_21>
<M_22>1</M_22>
</Rotation>
</RotatedBox3D>
</Object3D>
<Object3D id="9">
<LabelInfo>
<LabelId>29</LabelId>
</LabelInfo>
<RotatedBox3D>
<Box3D>
<xmin>20.9584511724897</xmin>
<ymin>12.319399747568</ymin>
<zmin>36.1015345364395</zmin>
<xmax>21.169238198679</xmax>
<ymax>12.4793676344069</ymax>
<zmax>36.9024438572005</zmax>
</Box3D>
<Rotation>
<M_00>-0.308218298834533</M_00>
<M_01>0.951315657530951</M_01>
<M_02>0</M_02>
<M_10>-0.951315657530951</M_10>
<M_11>-0.308218298834533</M_11>
<M_12>0</M_12>
<M_20>0</M_20>
<M_21>0</M_21>
<M_22>1</M_22>
</Rotation>
</RotatedBox3D>
</Object3D>
<Object3D id="17">
<LabelInfo>
<LabelId>30</LabelId>
</LabelInfo>
<RotatedBox3D>
<Box3D>
<xmin>-14.2911021167082</xmin>
<ymin>-12.3380719723964</ymin>
<zmin>36.6555384788507</zmin>
<xmax>-12.9469008563212</xmax>
<ymax>-11.719230718431</ymax>
<zmax>40.9274766268461</zmax>
</Box3D>
<Rotation>
<M_00>-0.635254915386682</M_00>
<M_01>0.772302526525104</M_01>
<M_02>0</M_02>
<M_10>-0.772302526525104</M_10>
<M_11>-0.635254915386682</M_11>
<M_12>0</M_12>
<M_20>0</M_20>
<M_21>0</M_21>
<M_22>1</M_22>
</Rotation>
</RotatedBox3D>
</Object3D>
</Objects>
</Objects3D>
</Annotations>
</ContextScene>
3D segmentation

To store one label per point in a point cloud, what is often called Semantic segmentation, we use the OPC format. This format with Level Of Details is designed to be streamed and efficiently displayed. Each point is decorated with a 16bit unsigned integer sets to its label. Like for 2D segmentation, the value 65535 is reserved for points where the label is unknown.
<?xml version="1.0" encoding="utf-8"?>
<ContextScene version="4.0">
<SpatialReferenceSystems>
<SRS id="0">
<Definition>ENU:49.14651925,-122.8868741</Definition>
</SRS>
<SRS id="1">
<Definition>EPSG:26910</Definition>
</SRS>
</SpatialReferenceSystems>
<Annotations>
<Labels>
<Label id="2">
<Name>ground</Name>
</Label>
<Label id="5">
<Name>high vegetation</Name>
</Label>
<Label id="14">
<Name>power_line</Name>
</Label>
<Label id="20">
<Name>bridge</Name>
</Label>
<Label id="6">
<Name>roof</Name>
</Label>
</Labels>
<Segmentation3D>
<SRSId>0</SRSId>
<Path>0:PointCloud.opc</Path>
</Segmentation3D>
</Annotations>
<References>
<Reference id="0">
<Path>F:\S3D_Graz\segmentedPointCloud</Path>
</Reference>
</References>
</ContextScene>
2D lines

The following annotations describe a set of lines in a plane, result of the analysis of an orthophoto, it might be cracks over a road, a road network, rails, etc. We call them lines though the topology required to describe these entities could be as complex as a graph with junctions, loops, etc. Hence, a Line2D is here given by a set of 2D vertices, and a set of segments between these vertices. To describe the "thickness" of the original entity which has been vectorized into a line, we use the mathematically sounded concept of diameter. It is the diameter of the largest disc centered at a given vertex containing only points of the entity. Here is a small example:
<?xml version="1.0" encoding="utf-8"?>
<ContextScene version="4.0">
<SpatialReferenceSystems>
<SRS id="0">
<Definition>EPSG:32615</Definition>
</SRS>
</SpatialReferenceSystems>
<Annotations>
<Labels>
<Label id="0">
<Name>background</Name>
</Label>
<Label id="1">
<Name>crack</Name>
</Label>
</Labels>
<Lines2D>
<SRSId>0</SRSId>
<Lines>
<Line2D id="0">
<LabelInfo>
<LabelId>1</LabelId>
</LabelInfo>
<Vertices>
<Vertex id="0">
<Position>
<x>479868.86</x>
<y>4980803.44157715</y>
</Position>
<Diameter>0.0202617157732701</Diameter>
</Vertex>
<Vertex id="1">
<Position>
<x>479868.712150948</x>
<y>4980803.47680339</y>
</Position>
<Diameter>0.0664043075900635</Diameter>
</Vertex>
<Vertex id="2">
<Position>
<x>479868.341404493</x>
<y>4980803.67640449</y>
</Position>
<Diameter>0.0686980153798615</Diameter>
</Vertex>
<Vertex id="3">
<Position>
<x>479868.468095477</x>
<y>4980803.63543635</y>
</Position>
<Diameter>0.0762712781246574</Diameter>
</Vertex>
</Vertices>
<Segments>
<Segment>
<VertexId1>0</VertexId1>
<VertexId2>1</VertexId2>
</Segment>
<Segment>
<VertexId1>1</VertexId1>
<VertexId2>3</VertexId2>
</Segment>
<Segment>
<VertexId1>2</VertexId1>
<VertexId2>3</VertexId2>
</Segment>
</Segments>
</Line2D>
<Line2D id="1">
<LabelInfo>
<LabelId>1</LabelId>
</LabelInfo>
<Vertices>
<Vertex id="0">
<Position>
<x>479874.427917961</x>
<y>4980802.47</y>
</Position>
<Diameter>0.0185410197570828</Diameter>
</Vertex>
<Vertex id="1">
<Position>
<x>479874.28053349</x>
<y>4980802.75</y>
</Position>
<Diameter>0.0339112355266864</Diameter>
</Vertex>
<Vertex id="2">
<Position>
<x>479874.373927691</x>
<y>4980802.67226102</y>
</Position>
<Diameter>0.0978553816042589</Diameter>
</Vertex>
<Vertex id="3">
<Position>
<x>479874.485410865</x>
<y>4980802.89236351</y>
</Position>
<Diameter>0.0908217292202603</Diameter>
</Vertex>
<Vertex id="4">
<Position>
<x>479874.37</x>
<y>4980802.64363961</y>
</Position>
<Diameter>0.0899999999783128</Diameter>
</Vertex>
<Vertex id="5">
<Position>
<x>479874.418415482</x>
<y>4980802.71591548</y>
</Position>
<Diameter>0.0813172786177372</Diameter>
</Vertex>
<Vertex id="6">
<Position>
<x>479874.83328093</x>
<y>4980803.53223969</y>
</Position>
<Diameter>0.0816060783607562</Diameter>
</Vertex>
<Vertex id="7">
<Position>
<x>479874.612768291</x>
<y>4980803.11426725</y>
</Position>
<Diameter>0.086105905882709</Diameter>
</Vertex>
<Vertex id="8">
<Position>
<x>479874.677758315</x>
<y>4980803.21801663</y>
</Position>
<Diameter>0.0872066516702332</Diameter>
</Vertex>
<Vertex id="9">
<Position>
<x>479874.55828698</x>
<y>4980802.99093257</y>
</Position>
<Diameter>0.0900163930024753</Diameter>
</Vertex>
<Vertex id="10">
<Position>
<x>479874.755737061</x>
<y>4980803.36709735</y>
</Position>
<Diameter>0.0900001483887829</Diameter>
</Vertex>
<Vertex id="11">
<Position>
<x>479874.456513669</x>
<y>4980802.78786825</y>
</Position>
<Diameter>0.0969726626446287</Diameter>
</Vertex>
</Vertices>
<Segments>
<Segment>
<VertexId1>0</VertexId1>
<VertexId2>4</VertexId2>
</Segment>
<Segment>
<VertexId1>1</VertexId1>
<VertexId2>2</VertexId2>
</Segment>
<Segment>
<VertexId1>2</VertexId1>
<VertexId2>5</VertexId2>
</Segment>
<Segment>
<VertexId1>2</VertexId1>
<VertexId2>4</VertexId2>
</Segment>
<Segment>
<VertexId1>3</VertexId1>
<VertexId2>9</VertexId2>
</Segment>
<Segment>
<VertexId1>3</VertexId1>
<VertexId2>11</VertexId2>
</Segment>
<Segment>
<VertexId1>5</VertexId1>
<VertexId2>11</VertexId2>
</Segment>
<Segment>
<VertexId1>6</VertexId1>
<VertexId2>10</VertexId2>
</Segment>
<Segment>
<VertexId1>7</VertexId1>
<VertexId2>9</VertexId2>
</Segment>
<Segment>
<VertexId1>7</VertexId1>
<VertexId2>8</VertexId2>
</Segment>
</Segments>
</Line2D>
<Lines>
</Lines2D>
</Annotations>
</ContextScene>
3D lines

The following annotations describe a set of lines in space. It might be cracks on a bridge, power-lines, rails, etc. Like in 2D, we call them lines but the topology required to describe these entities could be as complex as a graph with junctions, loops, etc. Hence, a Line3D is here given by a set of 3D vertices, and a set of segments between these vertices. If required, to describe the "thickness" of the original entity which has been vectorized into a line, we use the mathematically sounded concept of diameter. It is the diameter of the largest ball centered at a given vertex containing only points of the entity. Here is a small example:
<?xml version="1.0" encoding="utf-8"?>
<ContextScene version="4.0">
<SpatialReferenceSystems>
<SRS id="0">
<Definition>EPSG:32615</Definition>
</SRS>
</SpatialReferenceSystems>
<Annotations>
<Labels>
<Label id="1">
<Name>rail</Name>
</Label>
</Labels>
<Lines3D>
<SRSId>0</SRSId>
<Lines>
<Line3D id="1">
<LabelInfo>
<LabelId>1</LabelId>
</LabelInfo>
<Vertices>
<Vertex id="0">
<Position>
<x>3.27669495408764</x>
<y>-2.38028278379669</y>
<z>8.22511614762969</z>
</Position>
<Diameter>0.210008906878983</Diameter>
</Vertex>
<Vertex id="1">
<Position>
<x>3.22462717369163</x>
<y>-1.66835993119419</y>
<z>7.77181408678633</z>
</Position>
<Diameter>0.0646228165693428</Diameter>
</Vertex>
<Vertex id="2">
<Position>
<x>3.25055948322766</x>
<y>-2.50779389081678</y>
<z>8.30674826296262</z>
</Position>
<Diameter>0.187586254181419</Diameter>
</Vertex>
<Vertex id="3">
<Position>
<x>3.24724600068194</x>
<y>-2.45077881319647</y>
<z>8.27142235557896</z>
</Position>
<Diameter>0.131823435832277</Diameter>
</Vertex>
</Vertices>
<Segments>
<Segment>
<VertexId1>0</VertexId1>
<VertexId2>3</VertexId2>
</Segment>
<Segment>
<VertexId1>0</VertexId1>
<VertexId2>1</VertexId2>
</Segment>
<Segment>
<VertexId1>0</VertexId1>
<VertexId2>2</VertexId2>
</Segment>
</Segments>
</Line3D>
</Lines>
</Lines3D>
</Annotations>
</ContextScene>
2D polygons

The following annotations describe a set of 2D polygons in space. It might be building contours, regions with rust, etc. A Polygon2D is defined by a set of 2D vertices and a set of closed lines, at least one outer boundary, and optionally several inner boundaries. Here is a small example:
<?xml version="1.0" encoding="utf-8"?>
<ContextScene version="4.0">
<SpatialReferenceSystems>
<SRS id="0">
<Definition></Definition>
</SRS>
</SpatialReferenceSystems>
<Annotations>
<Labels>
<Label id="0">
<Name>background</Name>
</Label>
<Label id="1">
<Name>Vegetation</Name>
<Contour>true</Contour>
</Label>
<Label id="2">
<Name>Building</Name>
</Label>
<Label id="3">
<Name>Grass</Name>
</Label>
<Label id="4">
<Name>Car</Name>
</Label>
<Label id="5">
<Name>Road</Name>
</Label>
</Labels>
<Polygons2D>
<SRSId>0</SRSId>
<Polygons>
<Polygon2D id="0">
<LabelInfo>
<LabelId>2</LabelId>
</LabelInfo>
<Height>420.04</Height>
<Vertices>
<Vertex id="0">
<Position>
<x>533590.737633621</x>
<y>5212422.93763362</y>
</Position>
</Vertex>
<Vertex id="1">
<Position>
<x>533600.137633621</x>
<y>5212428.53763362</y>
</Position>
</Vertex>
<Vertex id="2">
<Position>
<x>533597.137633621</x>
<y>5212428.83763362</y>
</Position>
</Vertex>
<Vertex id="3">
<Position>
<x>533601.152966436</x>
<y>5212432.04762955</y>
</Position>
</Vertex>
<Vertex id="4">
<Position>
<x>533603.937633621</x>
<y>5212431.03763362</y>
</Position>
</Vertex>
<Vertex id="5">
<Position>
<x>533603.937633621</x>
<y>5212430.23763362</y>
</Position>
</Vertex>
<Vertex id="6">
<Position>
<x>533605.488269949</x>
<y>5212432.49451427</y>
</Position>
</Vertex>
<Vertex id="7">
<Position>
<x>533603.437633621</x>
<y>5212435.13763362</y>
</Position>
</Vertex>
<Vertex id="11">
<Position>
<x>533597.566139143</x>
<y>5212440.94099575</y>
</Position>
</Vertex>
<Vertex id="12">
<Position>
<x>533597.235569462</x>
<y>5212441.80559382</y>
</Position>
</Vertex>
</Vertices>
<OuterBoundary>
<VertexIds>
<VertexId>0</VertexId>
<VertexId>1</VertexId>
<VertexId>2</VertexId>
<VertexId>3</VertexId>
<VertexId>4</VertexId>
</VertexIds>
</OuterBoundary>
<InnerBoundaries>
<InnerBoundary>
<VertexIds>
<VertexId>10</VertexId>
<VertexId>11</VertexId>
<VertexId>12</VertexId>
</VertexIds>
</InnerBoundary>
<InnerBoundary>
<VertexIds>
<VertexId>5</VertexId>
<VertexId>6</VertexId>
<VertexId>7</VertexId>
</VertexIds>
</InnerBoundary>
</InnerBoundaries>
</Polygon2D>
</Polygons>
</Polygons2D>
</Annotations>
</ContextScene>
Other annotations
Some types of annotation are not part of the ContextScene format yet. Since they are planned, and because workarounds are available, it seems important to mention them here:
- Positions:
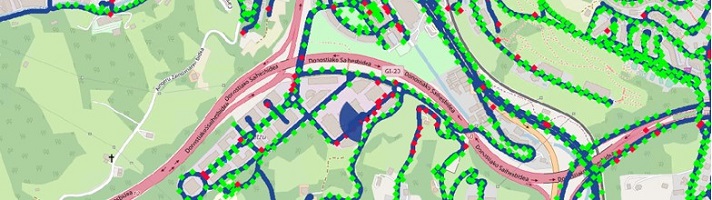
When the spatial extension of objects is useless but only their location is of interest, some Reality Analysis jobs export these positions in ESRI SHP files. This is not yet persisted in a ContextScene. A workaround so far is to the center point of their 3D boxes.
- Tags:
in some cases, no position at all is required, but just a list of labels. For instance: "this image contains people and cars". This case is not available yet and will be added.